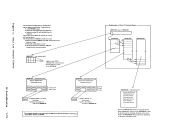
The channel check handler (CCH) aids the I/O supervisor (DMKIOS) to
recoverfrom channel errors. CCH provides the device-dependent error
recovery programs(ERPs) with the information needed to retry a channel
operation that has failed.
This support is standard and model-independent on the external level(from the user's point of view there are no considerations, at system generation time, for model dependencies) • SYSTEM INITIALIZATION FOR RMS DMKCPI calls DMKIOEFL to initialize the error recording at cold start
and warm start.DMKIOEFL gives control to DMKIOG to initialize the MCB area. A store CPU ID (STIDP) instruction is performed to determine if VM/370 is running in a virtual machine environment, or running
standalone on the realmachine. If VM/370 is running in a virtual
machine, the version code is set toX'FF' by DMKPRV. If the version
code returned isX'FF', the RMS functions are not initialized beyond
setting the wait bit on in the machine check newPSi (virtual). This occurs because machine check interruptions are not reflected to any
virtual machine.VM/370, running on the real machine, determines
whether the virtual machine should be terminated.
If the version code is notX'FF', DMKIOG determines what channels are
online by performing aStore Channel ID (STIDC) instruction and saves
the channel type for each channel that is online.The maximum machine check extended logout length (MCEL) indicated by the Store CPU ID (STIDP) instruction is added to the length of the MCH record header,
fixed logout length anddamage assessment data field. DMKIOG then calls DMKFRE to obtain the necessary storage to be allocated for the MCB record area (MCRECORD), the CP execution block (CPEXBLOK), MCHAREA, and MCEL. The address of MCHAREA is put in the PSI (ABCBAREA). Pointers to MCRECORD and the CPEXBLOK and put in MCHAREA. DMKIOG puts the address of !CEL in control register 15. DMKIOG obtains the storage for the I/O extended logout area and initializes the logout area and the ECSi to
ones. TheI/O extended logout pointer is saved at location 172 and
control register 15 is initialized with the address of the extended
logout area. The length of theCCB record and the online channel types
are saved inDMKCCH. It should be noted that the ability of a CPU to
produce an extended logout orI/O extended logout and the length of the
logouts are bothmodel- and channel-dependent. If VM/370 is· being
initialized on aModel 165 II or 168, the 2860, 2870, and 2880 standalone channel modules are loaded and locked by the paging
supervisor and the pointers are saved inDMKCCB. If VM/370 is being
initialized on any other model, the integrated channel support is
assumed; this support is part of the channel control subroutine ofDMKCCH. Before returning to DMKIOE, the VM/370 error recording
cylinders are initialized.DMKIOE passes control back to DMKCPI and
control register14 is initialized with the proper mask to record
machine checks.OVERVIEW OF MACBINE CHECK HANDLER
Amachine malfunction can originate from the processor, real storage or
control storage.When any of these fails to work properly, the processor
attempts to correct the malfunction.When the malfunction is corrected, the machine check handler (MCB) is
notified by amachine check interruption and the processor logs out
fields of information in real storage, detailing the cause and nature of
the error. The model-independent data is stored in the fixed logout area1-150 IBM VM/370 System Logic and Problem Determination--Voluae 1
recover
recovery programs
operation that has failed.
This support is standard and model-independent on the external level
and warm start.
standalone on the real
machine, the version code is set to
code returned is
setting the wait bit on in the machine check new
virtual machine.
whether the virtual machine should be terminated.
If the version code is not
online by performing a
the channel type for each channel that is online.
fixed logout length and
ones. The
control register 15 is initialized with the address of the extended
logout area. The length of the
are saved in
produce an extended logout or
logouts are both
initialized on a
supervisor and the pointers are saved in
initialized on any other model, the integrated channel support is
assumed; this support is part of the channel control subroutine of
cylinders are initialized.
control register
machine checks.
A
control storage.
attempts to correct the malfunction.
notified by a
fields of information in real storage, detailing the cause and nature of
the error. The model-independent data is stored in the fixed logout area