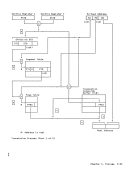
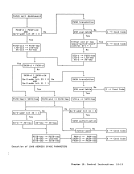
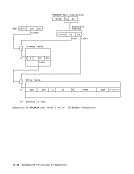
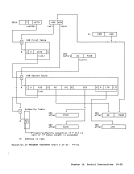
out of three, thus correcting a single
failure. An arrangement for correction
of failures of one order and for
detection of failures of a higher order
is called error checking and correction(ECC). Commonly, ECC allows correction
of single-bit failures and detection of
double-bit failures.
Depending on the model and the portion
of the machine in whichECC is applied,
correction maybe reported as system
recovery, or no report may be given.Uncorrected errors in storage and in the
storage key may be reported, along with
a failing-storage address, to indicate
where the error occurred. Depending on
the situation, these errors may be
reported along with system recovery,
with external secondary report, or with
the damage or backup condition resulting
from the error.CPU RETRY
In some models, information about some
portion of the state of the machine is
saved periodically. The point in the
processing at which this information is
saved is called a checkpoint. The
information saved is referred to as the
checkpoint information. The action of
saving the information is referred to as
establishing a checkpoint. The action
of discarding previously saved informa
tion is called invalidation of the
checkpoint information. The length of
the interval between establishing check
points is model-dependent.Checkpoints may be established at the beginning of
each instruction or several times within
a single instruction, or checkpoints may
be established less frequently.
Subsequently, this saved information may
be used to restore the machine to the
state that existed at the time when the
checkpoint was established. After
restoring the appropriate portion of the
machine state, processing continues from
the checkpoint. The process of restor
ing to a checkpoint and then continuing
is calledCPU retry. CPU retry may be used for machine-check
recovery, to effect nullification and
suppreSSlon of instruction execution
when certain program interruptions
occur, and in other model-dependent
situations.
Effects ofCPU Retry CPU retry is, in general, performed so
that there is no effect on the program.
However, change bits which have been
changed from zeros to ones are not
necessarily set back to zeros. As a
result, change bitsm~y appear to be set
to ones for blocksw~ich would have been
accessed ifrestori~g to the checkpoint
had not occurred. If the path taken by
the program;s dependent on information
that may be changed by anotherCPU or by
a channel or if an interruption occurs,
then the final path taken by the program
may be different from the earlier path;
therefore, change bits may be ones
because of stores along a path apparent
ly never taken.Checkpoint synchronization consists in
the following steps.
1. TheCPU operation is delayed until
all conceptually previous accesses
by thisCPU to storage have been
completed, both for purposes of
machine-check detection and as
observed by otherCPUs and by chan
nels.
2. All previous checkpoints, if any,
are canceled.
3. Optionally, a new checkpoint is
established. TheCPU operation is
delayed until all of these actions
appear tobe completed, as observed
by otherCPUs and by channels.
Handling of MachineChecks during Check point Synchronization
When, in the process of completing all
previous stores as part of the
checkpoint-synchronization action, the
machine is unable to complete all stores
successfully but can successfully
restore the machine to a previous check
point, processing backup is reported.
When, in the process of completing all
stores as part of the checkpoint
synchronization action, the machine is
unable to complete all stores success
fully and cannot successfully restore
the machine to a previous checkpoint,
the type of machine-check-interruption
condition reported depends on the origin
of the store. Failure to successfully
complete stores associated with instruc
tion execution may be reported as
instruction-processing damage, or some
less critical machine-check-interruption
condition may be reported with the
storage-Iogical-validity bit set to
zero. A failure to successfully
complete stores associated with the
execution of an interruption, other than
program or supervisor call, is reported
as system damage.Chapter 11. Machine-Check Handling 11-3
failure. An arrangement for correction
of failures of one order and for
detection of failures of a higher order
is called error checking and correction
of single-bit failures and detection of
double-bit failures.
Depending on the model and the portion
of the machine in which
correction may
recovery, or no report may be given.
storage key may be reported, along with
a failing-storage address, to indicate
where the error occurred. Depending on
the situation, these errors may be
reported along with system recovery,
with external secondary report, or with
the damage or backup condition resulting
from the error.
In some models, information about some
portion of the state of the machine is
saved periodically. The point in the
processing at which this information is
saved is called a checkpoint. The
information saved is referred to as the
checkpoint information. The action of
saving the information is referred to as
establishing a checkpoint. The action
of discarding previously saved informa
tion is called invalidation of the
checkpoint information. The length of
the interval between establishing check
points is model-dependent.
each instruction or several times within
a single instruction, or checkpoints may
be established less frequently.
Subsequently, this saved information may
be used to restore the machine to the
state that existed at the time when the
checkpoint was established. After
restoring the appropriate portion of the
machine state, processing continues from
the checkpoint. The process of restor
ing to a checkpoint and then continuing
is called
recovery, to effect nullification and
suppreSSlon of instruction execution
when certain program interruptions
occur, and in other model-dependent
situations.
Effects of
that there is no effect on the program.
However, change bits which have been
changed from zeros to ones are not
necessarily set back to zeros. As a
result, change bits
to ones for blocks
accessed if
had not occurred. If the path taken by
the program;s dependent on information
that may be changed by another
a channel or if an interruption occurs,
then the final path taken by the program
may be different from the earlier path;
therefore, change bits may be ones
because of stores along a path apparent
ly never taken.
the following steps.
1. The
all conceptually previous accesses
by this
completed, both for purposes of
machine-check detection and as
observed by other
nels.
2. All previous checkpoints, if any,
are canceled.
3. Optionally, a new checkpoint is
established. The
delayed until all of these actions
appear to
by other
Handling of Machine
When, in the process of completing all
previous stores as part of the
checkpoint-synchronization action, the
machine is unable to complete all stores
successfully but can successfully
restore the machine to a previous check
point, processing backup is reported.
When, in the process of completing all
stores as part of the checkpoint
synchronization action, the machine is
unable to complete all stores success
fully and cannot successfully restore
the machine to a previous checkpoint,
the type of machine-check-interruption
condition reported depends on the origin
of the store. Failure to successfully
complete stores associated with instruc
tion execution may be reported as
instruction-processing damage, or some
less critical machine-check-interruption
condition may be reported with the
storage-Iogical-validity bit set to
zero. A failure to successfully
complete stores associated with the
execution of an interruption, other than
program or supervisor call, is reported
as system damage.